Example of Our proposed painting synthesization places transparent triangles to fit a concept.
Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts
Abstract
Evolutionary algorithms have been used in the digital art scene since the 1970s. A popular application of genetic algorithms is to optimize the procedural placement of vector graphic primitives to resemble a given painting. In recent years, deep learning-based approaches have also been proposed to generate procedural drawings, which can be optimized using gradient descent.
In this work, we revisit the use of evolutionary algorithms for computational creativity. We find that modern evolution strategies (ES) algorithms, when tasked with the placement of shapes, offer large improvements in both quality and efficiency compared to traditional genetic algorithms, and even comparable to gradient-based methods. We demonstrate that ES is also well suited at optimizing the placement of shapes to fit the CLIP model, and can produce diverse, distinct geometric abstractions that are aligned with human interpretation of language.
Introduction
Staring from early 20th-century in the wider context of modernism
The idea of minimalist art has also been explored in computer art with a root in mathematical art

|
With the recent resurgence of interest in evolution strategies (ES) in the machine learning community
| Prompt | Evolved Results |
| "Self" | |
| "Walt Disney World" | |
| "The corporate headquarters complex of Google located at 1600 Amphitheatre Parkway in Mountain View, California." |
We show that ES is also well suited at optimizing the placement of shapes to fit the CLIP
Modern Evolution Strategies based Creativity
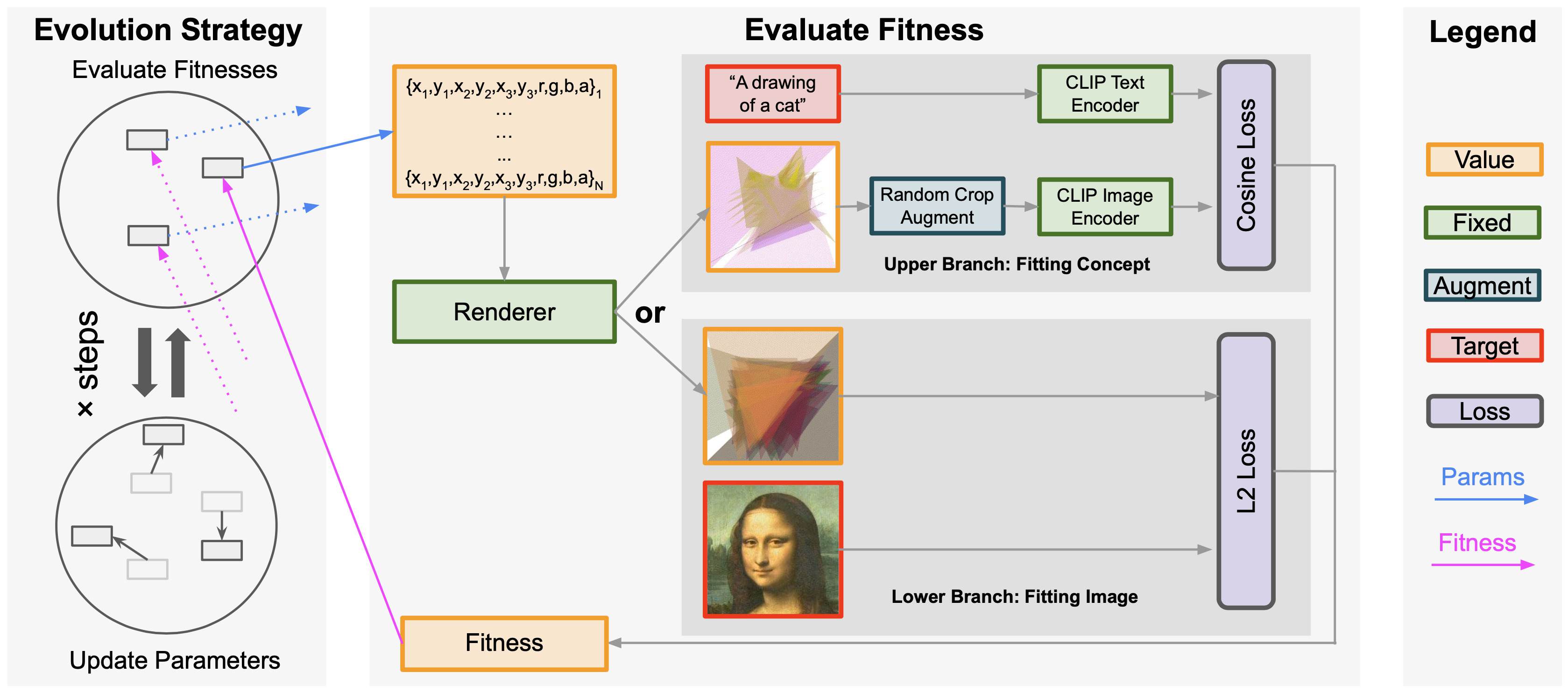
The architecture of our proposed is shown in Figure: The architecture of our method above.
Our proposed method synthesizes painting by placing transparent triangles using evolution strategy (ES).
Overall, we can represent a configuration of triangles in a parameter space which composes of positions and colors of triangles,
render such configuration onto a canvas,
and calculate its fitness based on how well the rendered canvas fits a target image or an concept in the form of a text prompt.
The ES algorithm keeps a pool of candidate configurations and uses mutations to evolves better ones measured by the said fitness.
To have better creative results, we use a modern ES algorithm, PGPE
As we choose to follow the spirit of minimalist art, we use transparent triangles as the parameter space. Concretely, a configuration of triangles is parameterized by a collection of for each of the triangles, which are vertex coordinates and the RGBA (Red, Green, Blue, and Alpha a.k.a. transparency channel) color, totally making parameters. In the ES, we update all parameters and use a fixed hyper-parameter, the number of triangles . Note that is better understood as the upper bound of number of triangles to use: although is fixed, the algorithm is still capable of effectively using "fewer" triangles by making unwanted ones transparent.
As the ES is orthogonal to the concrete fitness evaluation, we are left with many free choices regarding what counts as fitting.
Particularly, we consider two kinds of fitness, namely, fitting a concrete image and fitting a concept (the lower branch and the upper branch in Figure: The architecture of our method above respectively).
Fitting a concrete image is straightforward, where we can simply use the pixel-wise L2 loss between the rendered canvas and the target image as the fitness.
Fitting a concept requires more elaboration. We represent the concept as a text prompt and embed the text prompt using the text encoder in CLIP
We find in practice a few decisions should be made so the whole pipeline can work reasonably well.
First, we augment the rendered canvas by random cropping in calculating the fitness and average the fitness on each of the augmented canvas, following the practice of
Fitting Concrete Target Image
In this section, we show the performance of our proposed work on fitting a concrete target image. In doing so, the model takes the lower branch in the architecture of our method we show the result fitting the famous painting "Mona Lisa" with triangles and running evolution for steps in Figure: Our method fitting painting "Mona Lisa" earlier in the text. The results show a distinctive art style represented by well-placed triangles that care both fine-grained textures and large backgrounds. The evolution process also demonstrates the coarse-to-fine adjustment of triangles' positions and colors.
| Target Image | 10 Triangles | 25 Triangles | 50 Triangles | 200 Triangles |

|
||||
| "Darwin" | Fitness = 96.82% | Fitness = 99.25% | Fitness = 99.51% | Fitness = 99.75% |
|
|
||||
| "Mona Lisa" | Fitness = 98.02% | Fitness = 99.30% | Fitness = 99.62% | Fitness = 99.80% |

|
||||
| "Anime Face" | Fitness = 94.97% | Fitness = 98.17% | Fitness = 98.80% | Fitness = 99.07% |

|
||||
| "Landscape" | Fitness = 97.07% | Fitness = 98.83% | Fitness = 99.08% | Fitness = 99.25% |

|
||||
| "Impressionism" | Fitness = 98.82% | Fitness = 99.23% | Fitness = 99.34% | Fitness = 99.48% |
Number of triangles and parameters. Our proposed pipeline is able to fit any target images and could handle a wide range of number of parameters, since PGPE runs efficiently, i.e., linear to the number of parameters. This is demonstrated by applying our method to fit several target images with , , , triangles, which corresponds to , , and parameters respectively. As shown in Figure: Qualitative and quantitative results from fitting target images with different number of triangles above, our proposed pipeline works well for a wide range of target images, and the ES algorithm is capable of using the number of triangles as a "computational budget" where extra triangles could always be utilized for gaining in fitness. This allows a human artist to use the number of triangles in order to find the right balance between abstractness and details in the produced art.
| Target Image | Ours (10k iters) | Basic (10k iters) | Basic (560k iters) |
|
|
|
Choice of ES Algorithm.
We compare two choices of evolution algorithm: ours, which uses the recent PGPE with ClipUp, and a basic, traditional one, which consists of mutation and simulated annealing adopted earlier
| Target Image | Evolution Strategy (Non-gradient) |
Differentiable Renderer (Gradient-based) |
|
|
Comparison with Gradient-based Optimization.
While our proposed approach is ES-based, it is interesting to investigate how it compares to gradient-based optimization since the latter is commonly adopted recently.
Therefore we conduct a gradient-based setup by implementing rendering of composed triangles using nvdiffrast
Fitting Abstract Concept with CLIP
In this section, we show the performance of our method configured to fit an abstract concept represented by language. In doing so, the model takes the upper branch in Figure: The architecture of our method above. Formally, the parameter space remains the same, but the fitness is calculated as the cosine distance between the text prompt and the rendered canvas, both encoded by CLIP. Since the model is given more freedom to decide what to paint, this problem is arguably a much harder yet more interesting problem than fitting concrete images in the previous section.
In Figure: ES and CLIP fit the concept represented in text prompt earlier in the text, we show the evolution result and process of fitting abstract concept represented as text prompt, using 50 triangles and running evolution for steps.
We found that unlike fitting a concrete images, steps is enough for fitting a concept to converge.
Our method could handle text prompts ranging from a single word to a phrase, and finally, to a long sentence, even though the task itself is arguably more challenging than the previous one.
The results show a creative art concept that is abstract, not resembling a particular image, yet correlated with humans' interpretation of the text.
The evolution process also demonstrates iterative adjustment, such as the human shape in the first two examples, the shape of castles in Disney World, as well as in the final example, the cooperate-themed headquarters.
Also, compared to fitting concrete images in the previous section, our method cares more about the placement of triangles.
| Prompt | 10 Triangles | 25 Triangles | 50 Triangles | 200 Triangles |
| "Self" | ||||
| "Human" | ||||
| "Walt Disney World" | ||||
| "A picture of Tokyo" | ||||
|
"The corporate headquarters complex of Google located at 1600 Amphitheatre Parkway in Mountain View, California."
|
||||
|
"The United States of America commonly known as the United States or America is a country primarily located in North America."
|
Number of triangles and parameters. Like fitting a concrete image, we can also fit an abstract concept with a wide range of number of parameters since the PGPE algorithm and the way we represent canvas remains the same. In Figure: Qualitative results from ES and CLIP fitting several text prompt with different numbers of triangles above, we apply our method to fit several concept (text prompt) with , , , triangles, which corresponds to , , and parameters respectively. It is shown that our proposed pipeline is capable of leveraging the number of triangles as a "budget for fitting" to balance between the details and the level of abstraction. Like in the previous task, this allows a human artist to balance the abstractness in the produced art.
We observe that while the model could comfortably handle at least up to triangles, more triangles () sometimes poses challenges: for example, with triangles, "corporate headquarters ..." gets a better result while "a picture of Tokyo" leads to a poor one. This may be due to the difficulties composing overly shadowed triangles, and we leave it for future study.
| Prompt | 4 Individual Runs | |||
| "Self" | ||||
| "Human" | ||||
| "Walt Disney World" | ||||
| "A picture of Tokyo" | ||||
|
"The corporate headquarters complex of Google located at 1600 Amphitheatre Parkway in Mountain View, California."
|
||||
|
"The United States of America commonly known as the United States or America is a country primarily located in North America."
|
||||
Multiple Runs. Since the target is an abstract concept rather than a concrete image, our method is given much freedom in arranging the configuration of triangles, which means random initialization and noise in the optimization can lead to drastically different solutions. In Figure: Qualitative results from ES and CLIP fitting several text prompt with different numbers of triangles above , we show 4 separate runs of our method on several text prompts, each using triangles with iterations, which is the same as previous examples. As shown, our method creates distinctive abstractions aligned with human interpretation of language while being capable of producing diverse results from the same text prompt. This, again, is a desired property for computer-assisted art creation, where human creators can be put "in the loop", not only poking around the text prompt but also picking the from multiple candidates produced by our method.
| Prompt | Evolution Strategy (Non-gradient) |
Differentiable Renderer (Gradient-based) |
| "Self" | ||
| "Walt Disney World" |
Comparison with Gradient-based Optimization.
With CLIP in mind, we are also interested in how our ES-based approach compares to the gradient-based optimization, especially since many existing works
As shown in Figure: Evolution strategies vs. differentiable renderer for CLIP, while both our ES method and the differentiable method produce images that are aligned with human interpretation of the text prompt, ours produces more clear abstraction and clear boundaries between shapes and objects. More interestingly, since ours represents an art style closely resembling abstract expressionism art, the difference between ours and the differentiable rendered is similar to that between post-impressionism and impressionism, where bolder geometric forms and colors are used. Like the counterpart comparison in fitting a concrete image, we argue that such results are intrinsically rooted in the optimization mechanism, and our proposed method leads to a unique art style through our design choices.
Related Works and Backgrounds of our Work
Realted Works
Generating procedural drawings by optimizing with gradient descent using deep learning has has been attracting attention in recent years
A growing list of works
Perhaps the closest to our approach among the related works is
Backgrounds of our Work
Evolution Strategies (ES)
Since PGPE runs linear to the number of parameters for each iteration, it is an efficient and the go-to algorithm in many scenarios.
With the estimated gradients, gradient-based optimizers such as Adam
Language-derived Image Generation has been seeing very recent trends in creativity setting, where there are several directions to leverage CLIP
Discussion and Conclusion
In this work, we revisit evolutionary algorithms for computational creativity by proposing to combine modern evolution strategies (ES) algorithms with the drawing primitives of triangles inspired by the minimalism art style. Our proposed method offers considerable improvements in both quality and efficiency compared to traditional genetic algorithms and is comparable to gradient-based methods. Furthermore, we demonstrate that the ES algorithm could produce diverse, distinct geometric abstractions aligned with human interpretation of language and images. Our finds suggests that ES method produce very different and sometimes better results compared to gradient based methods, arguably due to the intrinsical behavior of the optimization mechanism. However it remains an open problem to understand how in general setting ES method compares with gradient methods. We expect future works investigate further into broader spectrum of art forms beyond the minimalism explored here.
Our dealing with evolutionary algorithms provides an insight into a different paradigm that can be applied to computational creativity. Widely adopted gradient-based methods are fine-tuned for specific domains, i.e., diff rendering for edges, parameterized shapes, or data-driven techniques for rendering better textures. Each of the applications requires tunes and tweaks that are domain-specific and are hard to transfer. In contrast, ES is agnostic to the domain, i.e., how the renderer works. We envision that ES-inspired approaches could potentially unify various domains with significantly less effort for adaption in the future.